これはSmartHR Advent Calendar 2022 17日目のエントリーです。
こんにちは、SmartHRで文書配付機能の開発をしているmiyoshiと申します。 今回は私が担当している文書配付機能で繁忙期を乗り越えるためにやった負荷テストの話を共有しようと思います。 この記事では我々がどのように考え負荷テストを進めてきたかを書いていますので、負荷テストをやるべきか悩んでいる人の助けになれば幸いです。
背景
文書配付機能は3月末から4月初頭にかけて繁忙期を迎えます。 これは新入社員の雇用契約書・誓約書や従業員の給与改定通知書など、この時期に送付・合意してもらいたい書類が数多く存在するためです。 恥ずかしながら昨年の4月はサーバーダウンを発生させてしまい迷惑をかけてしまったので、「今年はなんとしてでもサービスを継続させるんだ!」という想いがチーム内で強まっていました。 しかし、チーム内でインフラ面に明るいエンジニアが少なく、昨年よりも文書配付機能の利用者は増えている状況で本当に今年は大丈夫なのかという不安もありました。 そこで、事前に負荷テストを実施して確認しようとなりました。
「サーバーがダウンしているならば、どんな素晴らしい機能であっても顧客に価値を伝えられない」
詠み人知らず
負荷テストの設計
負荷テストにあたって、まずはどこにどれだけの負荷を与えるかといった、テスト設計から考えていきました。 幸いなことに弊社はNew Relicを導入しており、現状のアクセスを解析できます。 また、BigQuery, Redashにより過去にどれくらいのアクセスがあったかを統計的にも見えるようになっています。
チームでの議論を踏まえ今回の繁忙期に向けては次のようなテストにしました。
- テストシナリオ
- 従業員がログイン後、自分宛の書類を確認し、書類の内容に合意する
- 同時アクセス数
- 1時間あたり7000人
- テスト時間
- サーバーリソースを徐々に食い潰している場合を考慮し、負荷を15分以上かける
テスト結果
ここからは、負荷テストの結果について書いていきたいと思います。 負荷をかけるツールとしては今回locustを採用しました。 今回は特に複雑な要件とかもなく一連のテストシナリオをHTTPで再現できれば良かったので、自分達が使ってみたいツールを使いました。 (けっこう書き心地は良かったです)
結果
まず全体的なリクエスト数です。 GCPのMonitoring画面から引っ張ってきました。 最高で84.67rps(1分間あたりで換算すると5000request)の負荷をかけられているので、目標に対し十分な負荷をかけられつつ、その負荷にシステムが応答できている(サーバーダウンしてない)ことがわかります。

その時のError Rateです。 こちらはNew Relicから取ってきています。
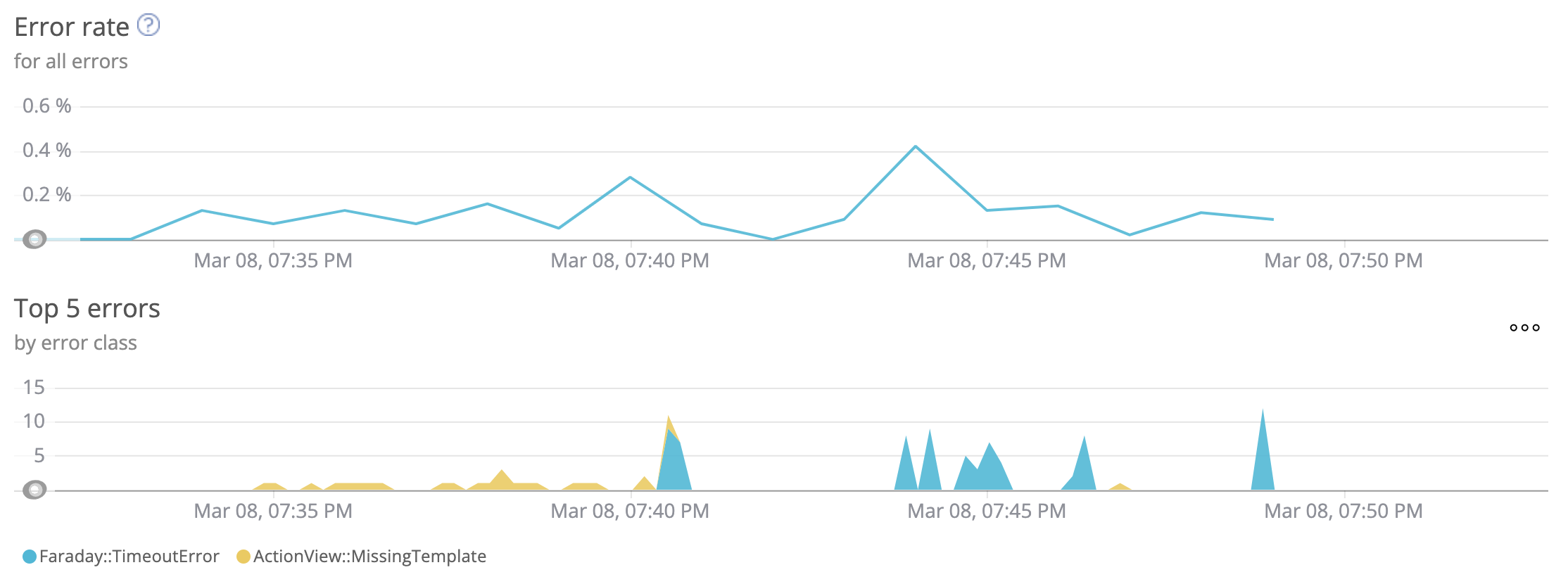
0.4%ほどエラーが発生していますが、内容がTimeout(と既知の軽微なエラー)なので十分理解を得られる範囲だと判断しました。
New Relicを使って、もう少し詳細に調べてみます。
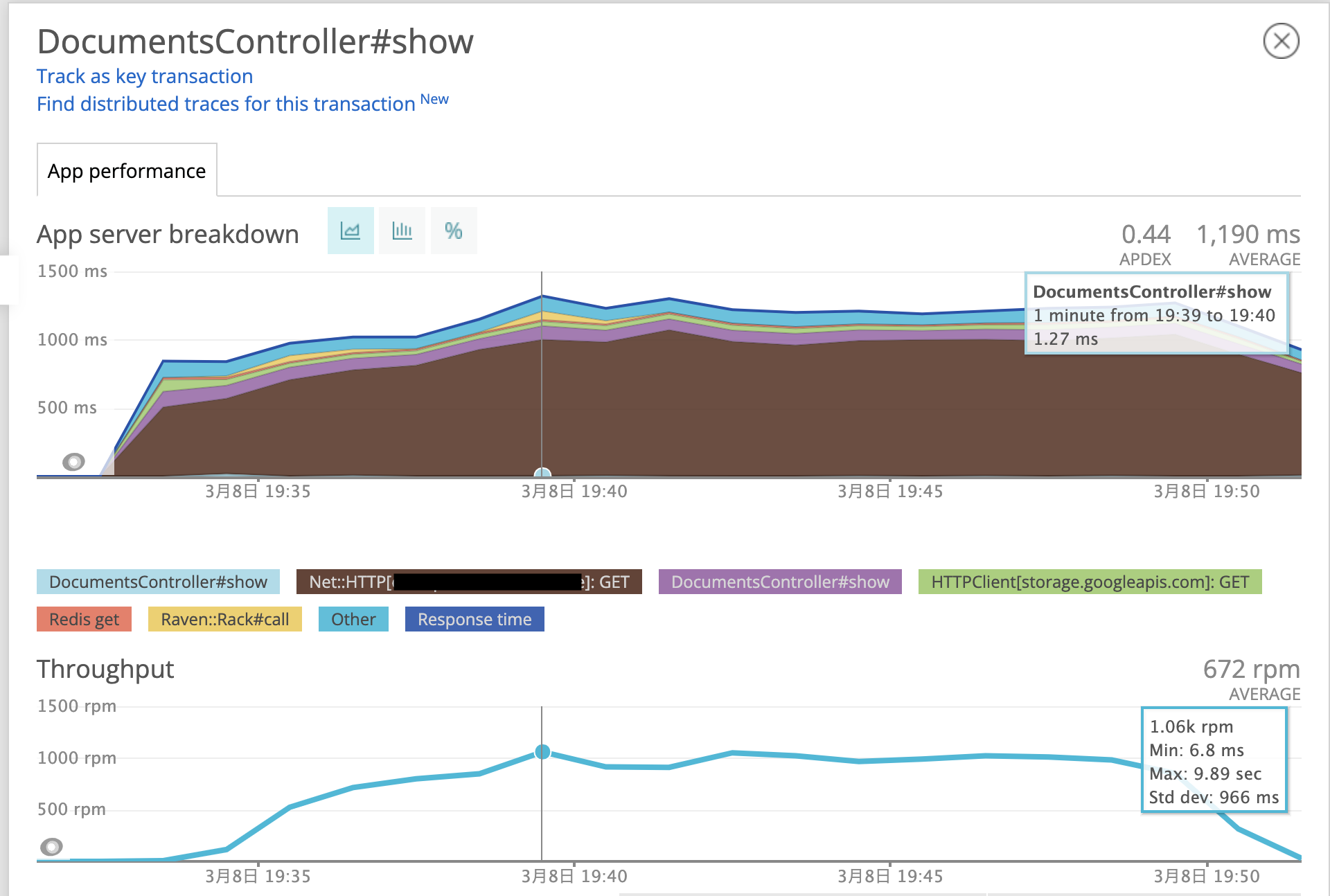
これはテストシナリオ中の「ユーザーが自分宛の書類を確認する」フェーズの状態です。 ある程度安定してリクエストを捌けており、最大で1060rpm(request per minute)を記録しています。 また、どの処理に時間がかかっているのかも視覚的にわかる(今回だと茶色い部分が多い)ので今後アプリケーションの性能を改善する際の参考にすることができます。
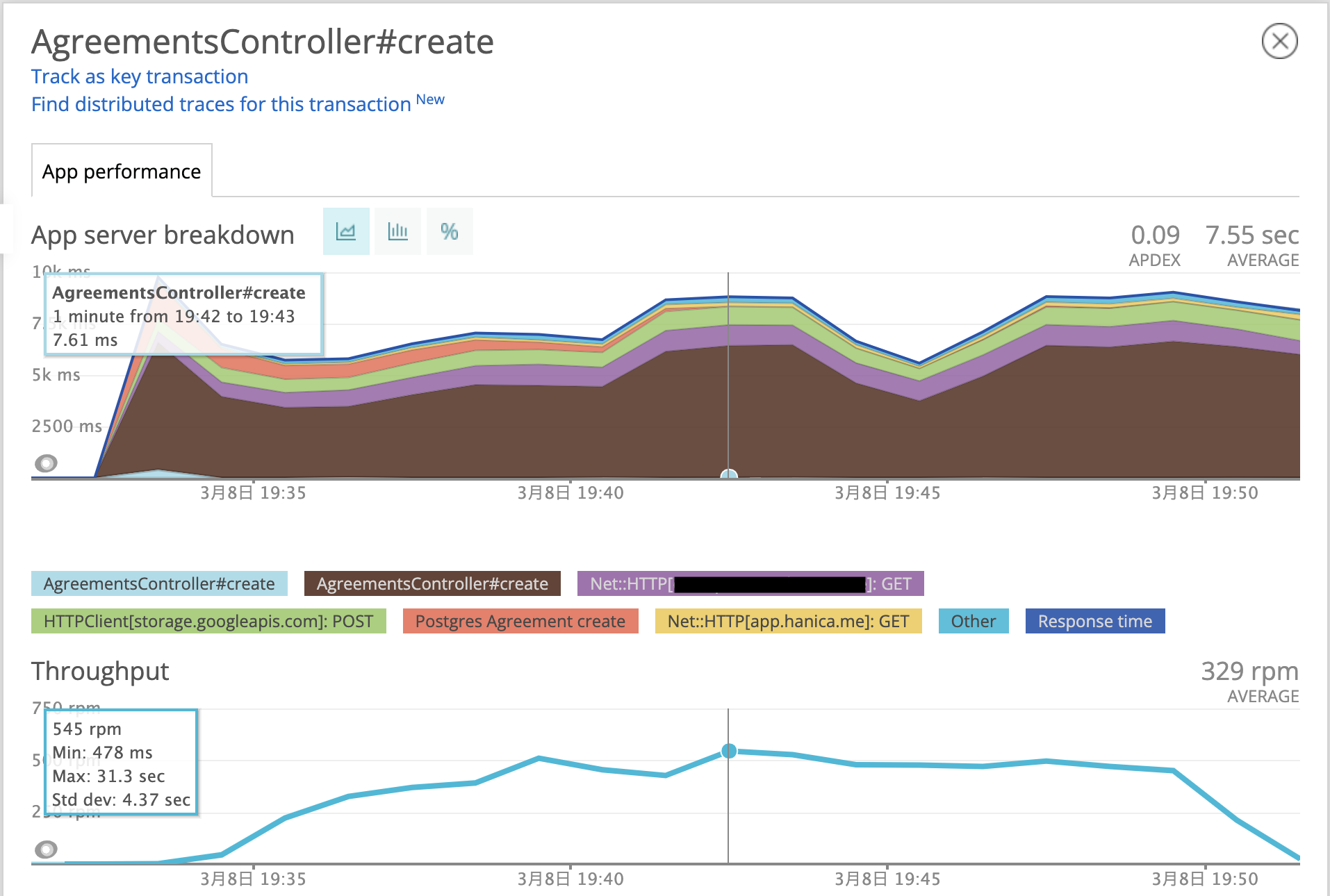
もう一つ、「書類に合意する」フェーズも見てみます。 書類の合意ではPDFファイルを生成したり、それに対して電子署名を付与したりなど重い処理が走るので、かなり値が悪くなって最大で545rpmでした。 また平均実行時間も7.55秒とだいぶかかっています。 結構遅いのでなんとかしたいのですが、今回はあくまで高負荷時にシステムが耐えられることを目標としていたので、別スコープとして考えることにしました
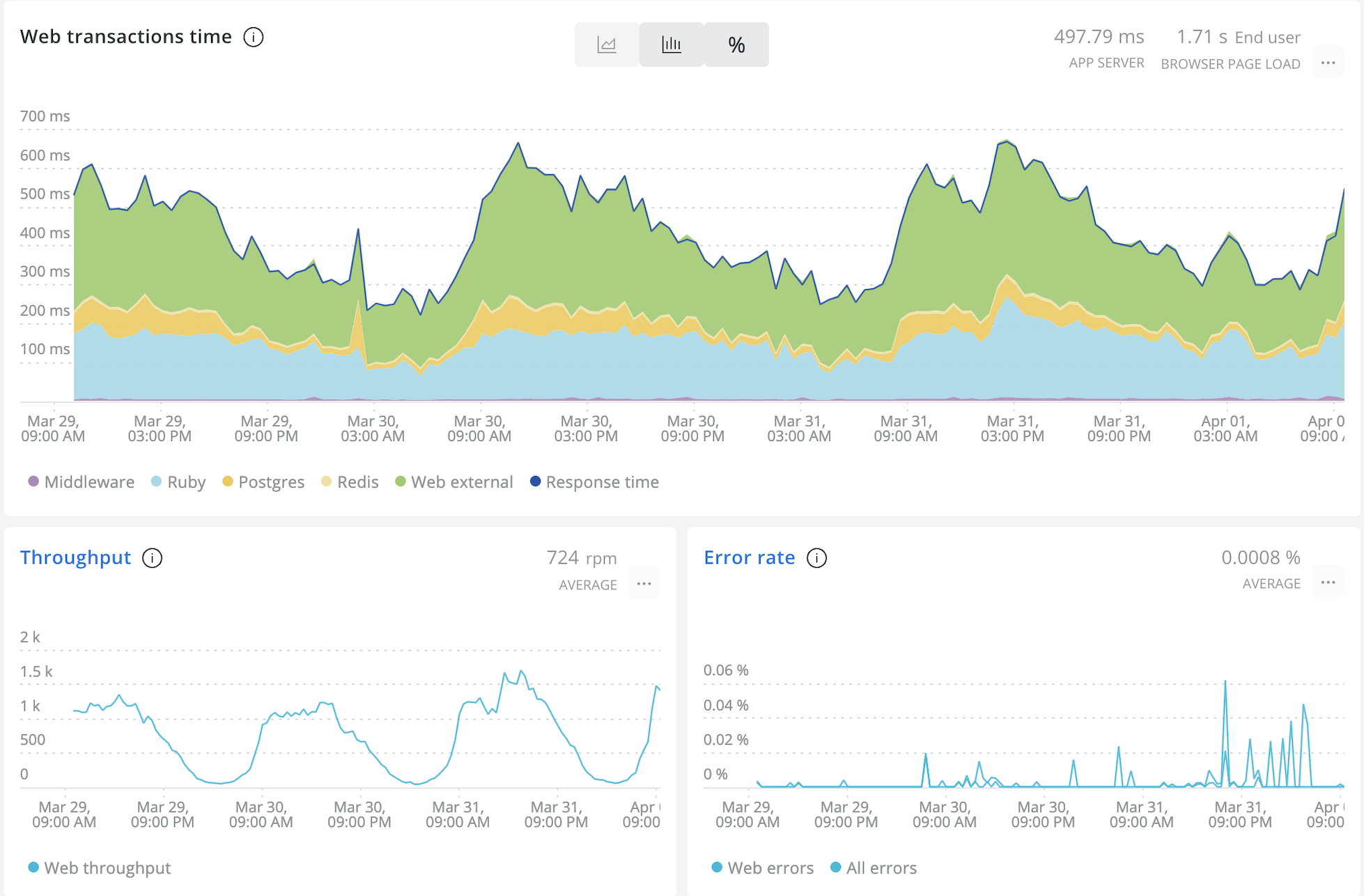
ちなみにこの後、「限界まで負荷を上げた場合どうなってしまうのだろう」という好奇心により、無茶苦茶に負荷をかけてみたのですが、文書配付機能より先に連携システムがサーバーダウンしました。 その際に文書配付機能のインフラリソースも上限に近い位置までスケールしていたので、リソース設計的にそこまで間違ってなさそうという知見も得られました。
負荷テストを終えての所感
事前に負荷テストをしたことで、昨年よりユーザー数が増えてるがシステムは耐えられそうであるという安心感を得られたことが大きかったです。 また、現在本番環境でMonitoringしているパラメータが、高負荷時にはどのようになって、その状況下で我々がどう対応したらいいかをあらかじめ訓練できたので、いざという時にも対応できそうだというのを実感できたのも非常によかったです。
実際どうだったのか
テストがうまく行ったからといって万々歳というわけではありません。 本来の目的は本番環境がアクセスが増えても落ちないようにすることです。 事前の負荷テストによって多分大丈夫だろうという結論が得られましたが、実際はどうだったのかをお伝えします。
やりました、完全勝利です。 一部レスポンスが遅くなるといった事象は確認しつつも、ほぼ全てのトラフィックを捌き切りサーバーエラーを発生させずに乗り切ることができました。
おまけ(負荷テスト時の失敗談)
実は負荷テストは1回で全てうまく行ったわけではなく、何度か失敗してリトライしていました。 同じ失敗を踏まなくていいように一部紹介したいと思います。
1. テスト環境が小さすぎた
今回負荷テストで使用したインフラ環境はいつも開発時に使っている環境を流用しました。 しかし、開発時には機能テストが主な用途なのでDBのサイズが非常に小さく、負荷をかけた段階で即死んでしまいました。
教訓1: テスト前にインフラのサイズが本番と同じか確認すべし
2. 一気に負荷をかけすぎた
最初はlocustの設定をpeak concurrency: 200, spawn rate: 20にしていました。 これは1秒あたり20人ずつアクセスを増やしていき、最大で200人同時にアクセスするといった内容です。 この設定だと同時に20人以上*1のログイン処理が走っており、負荷に耐えられなくてエラーが返ってきてました。 しかし、SmartHRはBtoB向けのアプリであるため、ある程度の時間の間にアクセスが集中することはあっても完全に同一のタイミングで多数のユーザーが同じ処理を行うことはほぼありません。 明らかに実態と違うテストとなってしまったため、spawn rateを下げて緩やかに負荷が増えていくように調整しました。
教訓2: テスト内容が実態を合っているかを検証すべし(BtoBのアプリではspawn rateは低めに設定した方が実態とあってそう)
3. 追試時に必要な事前準備を忘れてしまった
今回のテストシナリオでは従業員が自分の書類を確認するため、あらかじめ管理者から従業員の書類を送信しておく必要があります。 当然我々も手順書にそのことを記載していたのですが、複数回トライアンドエラーを繰り返しているうちにその処理を忘れてしまい、時間を無駄にしたことがありました。
教訓3: 手動でやることはチェックリストを作って試験前に確認できるようにすべし(2回目やるときは1回目のデータ分を空にしたり、別の列を作成したりなどちゃんと記録を残せるようにしたほうが良い)
*1:ログイン処理は少し時間がかかるため実際には20リクエストをはるかの超えるリクエスト数を捌いていたようです