
この記事はSmartHR Advent Calendar 2023シリーズ2の8日目の記事です。
こんにちは!SmartHRのプロダクトエンジニアのshunです。 突然ですが、皆さんはStorybookのモックデータをどのように用意していますか?この記事ではプロダクト開発でStorybookを活用する上で最適なモックデータとは何かを考えてみます。
Storybookとは
Storybookとは、UIコンポーネントをカタログ形式で表示し、実施にアプリケーションを起動せずともUIの開発を行えるようにするためのツールです。
SmartHR社内では複数のプロダクトにおいてStorybookが導入されており、Chromaticと組み合わせた画像回帰テスト(以下VRT(Visual Regression Test))による品質担保や、UIレビューの効率化等で活用されています。
StorybookとChromaticを組み合わせたVRTに関しては技術評論社のWEB+DB PRESS vol.134にて記事を書かせていただきました。詳しく知りたい方はそちらをご覧いただければと思います。
数字の連番や仮の文字列を使った場合
モックデータを考える上で、以下のPropsを持つUsersTableコンポーネントを例に考えてみます。
UsersTableは一覧表示するUserのリストを受け取り、テーブルに表示します。1
type User = { id: string empCode: string // 社員番号 name: string // 氏名 department: string // 部署 enteredAt: string // 入社日 employmentType: '正社員' | '契約社員' // 雇用形態 } type Props = { users: User[] } export const UsersTable: React.FC<Props> = ({ users }) => { ...
モックデータの検討に時間をかけずに最速でStoryを実装したい場合、以下のように連番などを使ってUserのインタフェースを充足させたモックデータを作るという方法があります。
const meta = { component: UsersTable, } satisfies Meta<typeof UsersTable> export default meta type Story = StoryObj<typeof meta> const usersMock: User[] = Array.from({ length: 10 }, (_, i) => ({ id: i.toString(), empCode: i.toString(), name: `氏名${i}`, department: `部署${i}`, employmentType: '正社員', enteredAt: new Date(2020, 0, i), })) export const Default: Story = { args: { users: usersMock, }, }
Storybook上の表示は以下のようになります。
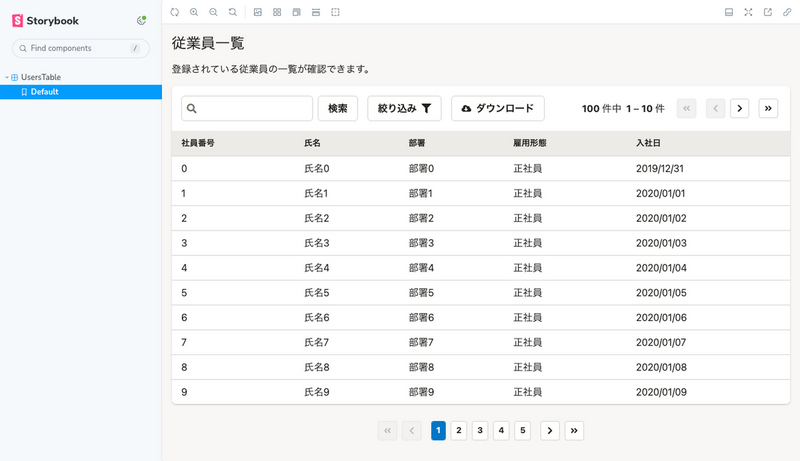
Storybook上では、従業員一覧のテーブルがSmartHRの「よくあるテーブル」パターンで実装されていることが確認できます。
これだけでも最低限のVRTは行なえますし、チームでのUIレビューも可能だとは思います。しかし、実運用で入りうるデータが使用されていないことで以下の問題が生じます。
- 明らかなダミーデータのため、列の幅の調整を含むスタイリングの調整や、その他UIに関するフィードバックを的確に行えない
- ヘルプページや営業資料で当該コンポーネントのスクリーンショットをそのまま利用できない
そのため、Storybookのモックデータを用意する際はできるだけ実運用で想定されるようなリアルなデータを用意することが望ましいと思います。
リアルなデータを用意した場合
リアルなモックデータを用意する方法ですが、プロダクトのフェーズによっていくつかやり方があり、一概にこのやり方が正しいというものは無いと思います。
例えば、プロダクトが既にリリースされているか、バックエンドと結合して動作する開発環境等がある場合、実際のプロダクト上でデータを作成し、APIのレスポンス等をそのままStory上にコピーして利用する方法もあります。
とはいえ、Storyを実装する段階では対象のコンポーネントがまだプロダクトに組み込まれていない場合も多々あると思うので、ここではStory上でリアルなデータを用意した場合の実装例を紹介します。
まずはモックデータの生成コードです。
const names = [ '田中 太郎', '山田 みゆき', '佐藤 健太', '鈴木 由美', '高橋 裕一', '渡辺 さくら', '伊藤 隆夫', '斉藤 美香', '木村 健一', '岡田 あさみ', ] const departments = [ '人事部', '開発部/システム開発課', '営業部/営業1課/関西営業部', '財務部', '研究開発部/先端技術研究室', '広報部', '製造部/生産計画課', '販売部/国際営業課', '企画部/新規事業開発室', '総務部/施設管理課', ] const usersMock: User[] = Array.from({ length: 10 }, (_, i) => ({ id: i.toString(), empCode: (i + 1).toString().padStart(6, '0'), name: names[i], department: departments[i], employmentType: i === 8 ? '契約社員' : '正社員', enteredAt: new Date(2020, 0, i), }))
namesやdepartmentsの生成ですが、ダミーデータを生成するライブラリなどで毎回ランダムに生成した場合、VRTが毎回コケてしまうなどの問題があるため、固定文字列で指定するのが良いでしょう。
また、上記コードでのnamesとdepartmentsに関しては雑にChatGPTに適当に生成してもらいました。

empCodeやemploymentTypeに関しても、実データで想定されている桁数や、値の出現頻度を想定して調整を行っています。
結果として、Storyの表示は以下のように改善されました。
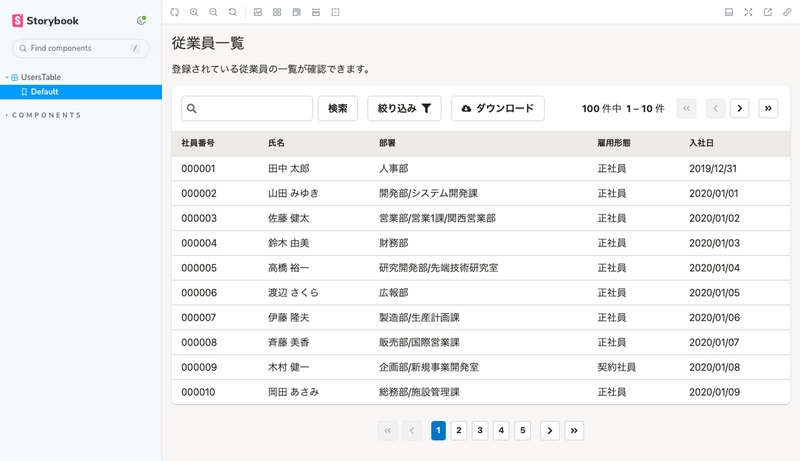
まだ詰めの甘いところはあるかもしれませんが、この程度の軽い改善を行うだけで先程のダミーデータの際の問題点が全て解消され、以下の付加価値も得ることが出来ます!
- 実データを想定したUIレビューが行える
- ヘルプページのスクリーンショットや、ユーザとのコミュニケーションにStorybookの画面をそのまま利用できる
まとめ
本記事では、Storyを実装する上で明らかなダミーデータではなく、リアルなデータを生成する方法やそれによって生まれる付加価値についてご紹介しました。
モックデータの取り扱いは、プロダクトのフェーズや、対象とするコンポーネント等によっても異なります。今回紹介した方法はあくまで一例として、チームでStorybookを運用していく上での一つの情報として活用していただければ幸いです。
We Are Hiring!
SmartHR では一緒に SmartHR を作りあげていく仲間を募集中です! 少しでも興味を持っていただけたら、カジュアル面談でざっくばらんにお話ししましょう!
-
UsersTableはSmartHRのプロダクトで実際に使われているコンポーネントではなく、本記事用に作成したサンプルコンポーネントです。↩