こんにちは。プロダクトエンジニアのcerisです。
今回は分析レポート機能のユーザーの利用傾向を把握するために利用しているRedashの運用を改善した際の取り組みを紹介します。
ちなみに私事ですがこうした社外向けのアウトプット記事を執筆するのは人生初です。お見苦しい文章が続くとは思いますが温かい目で読んでいただけると大変嬉しいです。
対象読者
- SmartHRのプロダクトがどのように利用者の傾向を把握しているのかに少しでも興味がある人
- Redashを利用している または丁度利用を検討していて運命的にこの記事に辿り着いている人
Redashとは?
BigQueryなどのデータソースと連携して、様々なデータを集計・可視化できるオープンソースのWEBアプリケーションです。
テーブル形式だけでなく棒グラフや円グラフ、散布図など様々なグラフがサポートされているので、かなり幅の広い可視化が可能です。
分析レポート機能(および弊社の他の多くのプロダクト)では、特定の機能の利用率やページビュー、アクティブユーザー数など、様々な情報を可視化しています。
これらのグラフをまとめたダッシュボードを作成して、グラフごとの傾向や推移などを確認したり、複数のグラフを掛け合わせて関連を探ってみたりしながら、正確な数値に基づいた改善の施策を打つといった取り組みを日々行っています。
あとこれは主目的ではないのですが、「今月受注テナント数がすごい伸びてる!!嬉しい!!!」みたいなチームのモチベーション向上のきっかけにもなっています。
Redashを利用する中で感じていたつらみ
上述したようにデータソースから必要な情報を取得してグラフィカルに可視化できる便利なツールですが、分析レポート機能の開発チームでの使い方とマッチしきらず、運用時につらみを感じることがありました。
特に苦労していた点を以下に書き出してみます。
つらみ1😫 汎用的なクエリの書き換えに苦労する 😫
弊社の場合、SmartHRプロダクト全体のほぼ全てのデータを単一のBigQueryに流し込んでいます。
そのため、分析レポート機能のために利用するクエリでは、まず分析レポート機能のデータのみを抽出するための汎用的なSQLを書くことになります。
なので、Redash上にクエリを作成するたびに汎用的なSQLが増殖していくわけなんですが、この汎用的なSQLに何か修正が必要となった際の修正作業が、まぁまぁな苦痛を強いる作業になってしまっていました。
RedashのUI上でひとつひとつクエリの編集画面に遷移して、修正箇所を頑張って見つけて直して実行してみて動作を確認して...という泥臭い作業をしなければならなかったのです。
直近の具体例では、分析レポート機能を含んでいる契約プランの名称が変更されたことに伴って、WHERE句で指定していたプラン名を置き換える作業を分析レポート機能のために作成した全てのクエリで修正する作業が発生しました。
現状はおよそ100件ほどのクエリを管理しています。そのすべてのクエリに対して個別にプラン名を書き換えて、念のため結果を確認して、保存して...という作業をしていることになります。仮にクエリ1つ更新するのに必要な作業が1分程度だったと仮定しても、完了まで数時間は掛かってしまいます。
これが1度だけならまだしも、細かい変更のたびに発生すると考えたらゾッとしませんか?
すべてのクエリを対象に文字列検索して一括置換が出来たら数分で終わるはずの作業に数時間掛けている状態は作業者に対してそれなりの負荷をかけていました。
つらみ2😫 変更履歴が確認できず、気軽に更新できない 😫
Redashのクエリは基本的にいつ誰が作ったのか・最後に更新したのはいつ誰なのかの情報しか見れません。
また、クエリも最新の状態しか確認できず、過去どういう状態だったのか、どこがどう変化したのかの差分は確認できません。
「一旦これで更新してみて、何週間か使ってみてダメそうだったら前の状態に切り戻そう」みたいなことがしたい時、変更履歴が確認できない場合はどこかに古いコードを保持しておく必要があります。
ただし、保持している間にクエリに対して別の変更が発生した場合など、切り戻し時に単純にコピペで戻せなくなるリスクは常にあるので、これはこれで戻すときに手間があります。
つらみ3😫 コードレビューができない 😫
Redashのクエリはプロダクション影響があるコードではなく運用利用目的であるため、普段の機能開発時と比べてレビューへの意識は低くなりがちではあるんですが、それに拍車を掛ける形でRedashのクエリはクロスチェックが難しい側面がありました。
まずは上述したようにクエリごとに編集画面に遷移しないとクエリが確認できないため、複数クエリを変更している場合はそれぞれのクエリを確認しに行く手間がかかります。また、変更履歴が確認できないので過去がどういう状態だったのかであったり、どこを修正したのかを把握するのは容易ではありません。
そして権限の問題もあります。Redashではクエリを作成したユーザーがauthorとして登録され、それ以外のユーザーは権限を都度アタッチされない限り閲覧権限しかありません。
そのためフィードバックをする前に挙動を確認したいなどの気持ちが湧いたときに、自分で一時的なクエリを作成してコピペして動作確認をするといった作業が必要になったり、とにかく不便が多いです。
仮に更新権限を付与されていたとして、レビュー中に動作を試すためにコードを変更した状態で誤って保存してしまうといったヒューマンエラーのリスクもあり、作業者が気を使う局面は多いです。
レビューをお願いするたびにこうした神経を使う作業を要求されるのはあまり良い体験ではなく、今思えばこれらもまたレビューへの意識の低下を招く要因になっていたように思います。
分析レポート機能の開発メンバーは頻繁にモブプロをするので、画面共有などをしながらクエリを書くという形でクロスチェックをしたり同時にコードレビューのような意味合いを持たせることもありますが、作業中は必ずしもレビュアーがレビューしたい箇所が画面共有されているとは限りません。
そのため「あー、もうちょっと上の方のコードが見たいです!あーーーー、もうちょっと下です!」みたいなコミュニケーションの負荷が高く、スムーズにレビュー出来る態勢とは言い難かったです。
つらみを解消するための"バージョン管理"
ここまで書いてきたつらみは「そのほとんどはSQLがリポジトリでバージョン管理されてさえいれば解決できるのでは?」というアイデアがチーム内で上がるようになってきました。
コードベースで管理されていればコード検索や一括置換は容易ですし、バージョン管理されていれば過去との比較や切り戻しも容易で、Pull Requestでレビューをしてから反映するフローを構築すれば、コードレビューも非常にやりやすくなります。
ただ、Redashのクエリを直接編集しなくなることによって考えられる課題もあって、「じゃあリポジトリで管理しているSQLをRedashのクエリに反映するのは自動化できるのか?もしそこが手動になってしまったら更新の手間が爆発的に増えて本末転倒では??」など懸念はいくつかありました。
とはいえ、RedashはAPIを公開していて、クエリ更新も可能そうなことは目星がついていたので、まずは出来ることから小さく始めてみることにしました。
運用方法の模索
SQLをバージョン管理出来ればつらみは解消できそうと言いつつ、それ以外のフローで新しいつらみが発生しては十分に運用に乗らない(不便さ次第では結局使われない)ことも十分に考えられたため、なるべく少ない手数でしっかりと管理できる運用方法を考える必要がありました。
長くなってしまうので整理した過程は省略しますが、大体こんな感じで運用したらストレスが少ないのでは?という方法を以下のように決めていきました。
- クエリの更新を行う場合、base branchから派生ブランチを作成して作業をする
- 特定のディレクトリ配下にSQLファイルを作成し、クエリを書く
- Redashの更新対象のクエリIDとリポジトリで管理しているSQLファイルのマッピングはリポジトリで管理する専用のjsonファイルによって行う
- 実装が終わったらPull Requestを作成し、メンバーからレビューをもらってからマージする
- GitHub Actionsによってbase branch向けのマージをトリガーにワークフローを実行
- 特定のディレクトリ配下の差分が発生しているSQLファイルを抽出(
gh pr diff --name-onlyコマンドで取得してから抽出する) - マッピング用のjsonからSQLファイル名で突合してRedashのクエリIDを取得する
- Redash APIのPOST:
/api/queries/<id>でクエリを更新するリクエストを発行する
- 特定のディレクトリ配下の差分が発生しているSQLファイルを抽出(
といった感じで、基本的にはマージ後の更新作業を自動化することで運用の負荷を感じさせない仕組みを考えました。
また、Redashの画面を一切開かずに作業が出来ないとあまり意味がないので、ローカル環境でクエリの実行結果を確認するためのスクリプトも用意する必要があります。これについては後述します。
実装
実装とは言ってもやっていることは「差分のあるクエリをマッピングして対応するクエリを書き換える」という要約すれば30文字で収まってしまうようなことをしているだけなので、実は運用イメージが固まってさえいればコードについてあまり書くことはないんですが、せっかくなのでディレクトリの構造を中心に実際のコードを公開しながら紹介します。
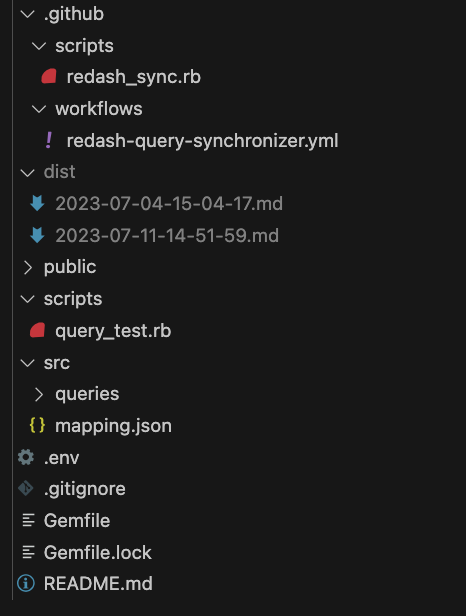
...とてもシンプルですね🌝
src/queries/[hoge].sql
src/queries/配下に配置しているSQLファイルがRedashに反映するクエリ群となります。
ファイル名はRedash側でクエリに設定するタイトルを指定すると更新作業時に対象を判断しやすくなります。
src/mapping.json
これがSQLファイルをRedashのどのクエリに対して適用するのかを紐づけるための情報となります。
今回は結構雑に作っていて、SQLファイル名をkeyに、RedashのクエリIDをvalueとして持つだけのシンプルな構造になっています。
{ "test_query.sql": 10 }
このようなデータを持たせておいて、ワークフローの方で「test_query.sqlに差分があったらそのファイルに記述されているSQLをRedashのクエリIDが10のものに対して更新してね」という命令ができるようにします。
.github/workflows/redash-query-synchronizer.yml
name: 🚀 Redash Query Synchronizer on: pull_request: types: - closed branches: - main jobs: synchronizer: if: github.event.pull_request.merged == true name: Query Synchronizer runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 with: fetch-depth: 0 - name: Sync Redash run: ruby .github/scripts/redash_sync.rb ${{github.event.number}} ${{ secrets.REDASH_API_KEY }} env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
base branch(mainブランチ)へのPull Requestのマージをトリガに実行するワークフローを定義しています。
このワークフローの仕事はとてもシンプルで、後述するredash_sync.rbに対してgithubのトークンと差分検索対象のPull Requestの番号を引数に渡して実行するだけです。
.github/scripts/redash_sync.rb
require "json" require "faraday" # 1️⃣ PRの変更ファイルリストから src/queries/ 配下のsqlファイルを抽出する pr_number = ARGV[0] api_key = ARGV[1] diff_files = %x(gh pr diff #{pr_number} --name-only).split("\n") target_files = diff_files.filter_map { |file| /\Asrc\/queries.*\.sql\z/.match?(file) && File.basename(file) } data = JSON.parse(File.read('src/mapping.json')) target_files.each do |target| # 2️⃣ mapping.json からファイルに関連づけたクエリIDを取得 query_id = data[target] # 3️⃣ 更新後のクエリ文字列を取得 query_text = File.read("src/queries/#{target}") # 4️⃣ クエリに変更がなければスキップ result = Faraday.get("https://<YOUR_REDASH_DOMAIN>/api/queries/#{query_id}?api_key=#{api_key}").body next if JSON.parse(result)['query'].gsub(/^-- (name|description):.*\n/, '') == query_text.gsub(/^-- (name|description):.*\n/, '') # 5️⃣ ロギングのための更新対象のクエリ情報を取得 result = Faraday.get("https://<YOUR_REDASH_DOMAIN>/api/queries/#{query_id}/results.json?api_key=#{api_key}").body result_json = JSON.parse(result)['query_result'] puts '更新対象のJSON' puts result_json # 6️⃣ クエリ更新のPOSTリクエストを送信 body = { "query" => %Q(#{query_text}) }.to_json Faraday.post("https://<YOUR_REDASH_DOMAIN>/api/queries/#{query_id}?api_key=#{api_key}", body) end
※弊社のRedashのドメイン部分は<YOUR_REDASH_DOMAIN>と置換しています🙏
このスクリプトが心臓部となる処理になります。
運用方法の模索の説明時にも書いたことの繰り返しになりますが、主に以下のような仕事をしています。
- gh pr diffでPull Requestの差分を抽出
- 更に
src/queries/配下のsqlファイルに絞り込み
- 更に
- 絞り込んだ結果に対して再帰的に以下の処理を行う
mapping.jsonに対応するkey(sqlファイルの名称)が存在する場合はvalueとして設定しているRedashのクエリIDを取得する- sqlを読み込んで、差分があればRedash APIを使って対応するクエリを更新するPOSTリクエストを発行する
(おまけ) scripts/query_test.rb
ローカル環境でクエリの実行を試したい場合にスクリプトを実行するだけで済ませたいなと思って用意したお便利スクリプトです。
Redash側にテスト専用のクエリを用意しておいて、そこに対してテストしたいSQLファイルの内容を雑にPOSTして実行して結果を取得、正常に結果が返ってきている場合はdist/配下にマークダウンのテーブル形式で出力するといった流れで処理をします。
運用に載せてみて
実を言うとバージョン管理の運用をし始めてからまだ数週間しか経っていないため、まだ少しずつ効果を実感し始めている段階ではあるんですが、上述していたつらみに関しては結構いい感じに解消できているんじゃないかという感覚を持っています。
実際にいくつか修正用のPull Requestをレビューしたんですが、圧倒的に差分比較がしやすいです。
やはりGitHubのUIには実家のような安心感がありますね。(これは人に依ります)
一方で、バージョン管理での運用に移行したことで感じ始めた課題もあって、折を見て解決策を考えたいものがあります。
まずPull RequestがマージされるまでRedash上に反映されないため単純に更新の気軽さが損なわれています。
base branchを最新にして派生ブランチを作成して〜〜というクエリ更新作業と関係がない手数を最初に踏む必要があるというのもつらいといえばつらいですね。
こうした手順も自動化していけるともう少し扱いやすくなるかもしれません。
また、運用をメンバー全員に浸透させるために少なからずコストが掛かる点も気になり始めました。僕はこれらの仕組みの基礎を作っていたこともあって運用方法は完全に理解しているんですが、そうでない人に対しては多少の学習コストを強いているような状況です。
READMEを用意してなるべく優しく手順を記載していたりはしますが、ローカル環境でクエリを実行するためのお便利スクリプトなどは存在に気づかれず、手動でクエリを作成してRedash上にコピペして実行していたメンバーもいたため、もう少し伝え方に工夫が必要かもしれないという感覚を持っています。
といった感じでまだまだ手探りの状態で課題もありますが、今後複数のクエリを一気にメンテナンスしたくなった場合などにおいては、真価を発揮してくれそうな手応えを感じています。
参考リンク
getredash/redash handlers/api.py
Redash APIのドキュメントは一部のエンドポイントしか記載されていないうえにパラメータやBODYのインターフェースもしっかり記載されていないため、リクエスト時に送信するパラメータやBODYの種類や型などの確認はソースコードを直接読みに行くのが一番早かったです。
最後に
以上、分析レポート機能の開発チームがRedashのクエリをバージョン管理するに至る取り組みの紹介でした。
プロダクトエンジニアはバージョン管理が大好き(諸説ある)なので、バージョン管理ができたことで変更履歴の確認や必要に応じた切り戻し、レビュー体制の強化による品質の確保など、色々と効果を実感できることに喜びを噛み締められるようになってきました!
バージョン管理体制に移行してからは全クエリの一括修正が必要な作業はまだ発生していないんですが、今後そういった作業が発生した場合は大粒の涙を流しながら過去の自分たちを褒めたくなるだろうと確信しています。
弊社では、こうした機能開発に留まらない運用の改善の取り組みなどもメンバー発案をきっかけに行っており、自律駆動で働きやすい環境を整備していきたい人にとっては魅力的な風土があると思っています。
SmartHRに興味を持っていただいた方・もっと詳しく話をききたいという方はぜひカジュアル面談でお会いしましょう!以下サイトからのご応募お待ちしています!