
こんにちは、@Tokky0425 です。
先日 SmartHR 社では「カスタム社員名簿」と「組織図」のサービス統合にあたって、前者から後者へのデータ移行を実施しました。
この記事では、その際に行ったいくつかの工夫を紹介したいと思います。
目次
前提の話
僕の所属する組織図機能開発チームでは、半年以上かけて「カスタム社員名簿」というサービスを「組織図」というサービスへ統合する作業を行っていました。
サービスの統合にまつわる開発トピックは大きく分けて2つあり、一つは「機能差分の解消」、もう一つは「データ移行」です。
機能差分の解消に関しては、Aにある機能をBにも作る、といった類のもので、普段の開発と大きく変わることはないのでイメージしやすいかと思います。
今回取り上げたいのは、もう一方の「データ移行」に関してです。
アプリケーションの規模によっては、サービス統合にあたって「Aというサービスは廃止になるので、これからはBを使ってね」というユーザーとのコミュニケーションもあるかとは思いますが、「カスタム社員名簿」は SmartHR の中で最も多くのユーザーに使われているオプション機能の一つです。「『カスタム社員名簿』は使えなくなるよ。同じ名簿データが欲しければ『組織図』上で同じものを手動で作ってね」という案内はあまりに影響が大きく、許容できるものではありませんでした。
そのため、我々は「カスタム社員名簿」のデータをできるだけそのままの形で「組織図」に移行する、「データ移行」までやる必要があったというわけです。
「データ移行」という作業は普段の開発の中でそんなに頻繁に発生するものではなく、チームに経験があるメンバーはいませんでした。この記事では、そんな中実践したいくつかの工夫を紹介します。
移行対象データをどれにするのよ問題
そもそもの話をすると、「カスタム社員名簿」は、名簿と呼ばれる単位で従業員のリスト形式のデータを作成・閲覧できる機能です。
そして、「組織図」機能内には「従業員を (組織図形式ではなく) 名簿形式で見る」という機能があり、データの移行後はこの機能を使ってユーザーは従業員名簿を閲覧できるようになります。
当初の案
プロジェクトが開始された当初のデータ移行のイメージは、
- データ移行を実行する日を予め決めておく
- 当日に、何かしらの方法によって「カスタム社員名簿」から「組織図」にデータを移行する
- この作業が終わり次第、ユーザーは「組織図」側で名簿データを閲覧できるようになる
というものでした。

ただし、移行のイメージをすり合わせて行くうちに、「どのデータを移行するかユーザーが選べるようにするべきなのではないか」という話が出てきました。
というのも、「昔は名簿機能を使ってたけど、今は使っていない」というユーザーにとっては、カスタム社員名簿の不要なデータが勝手に組織図に移行されてきたらノイズと感じるでしょうし、それらをわざわざ手動で削除するのも手間だからです。
次なる案
そこで出てきたのが、
- 「カスタム社員名簿」側に、移行データをどれにするかを選択できるようなページを作成する
- データ移行を実行する日には、チェックがついている名簿データを対象にデータ移行を実施する
という案です。

これによって、ユーザーは余計な名簿が移行されてしまうのを防げるようになります。
しかし、これでもまだ問題は解決とはなりませんでした。 データの閲覧範囲に関する概念が「カスタム社員名簿」と「組織図」では異なるので、データ移行前にそれらのマイグレーション作業をユーザーにやってもらう必要があるパターンがあることに気づいたからです。
こうなってくると、単に名簿一覧にチェックボックスの UI を追加するだけでなく、もっと大掛かりな「設定画面」的なものが必要になってきてしまいます。
また、データ移行実施日は決まっているので、ユーザーからしたら早くこのページにアクセスして余裕を持って移行対象を選択したり閲覧範囲の設定をしたくなるはずです。
一方、SmartHR としても、まだ統合のための機能差分の解消作業が残っている中、移行設定用のページを優先して取り組むというのはやや不安がありました。
最終案
そこで機転を利かせて出てきた案が、
- とりあえず全データ移行してしまう
- 移行先である「組織図」機能には「移行データ一覧」的な画面を追加しておく
- そこからユーザーは好きなタイミングで閲覧権限の設定をしたり、公開したりする
というものでした。

こうすることで、データ移行の実施日までユーザーは何もやることがなくなり、データ移行が実施されたあとから余裕を持って公開設定や閲覧範囲の設定をすることができます。
また、SmartHR としても、データ移行のためのユーザー向けの画面の作成を急いで作る必要がなくなり、統合に必要な目の前の機能差分の解消に優先的に取り組めるようになります。「移行データ一覧」画面をユーザーに公開する前であれば、移行時に発生したエラー調査などにも落ち着いて対応できるというのも嬉しいところです。
データ移行というと、「完璧な移行ロジックを書いたはず!頼む、データの不整合や意図しないデータの公開など起きないでくれ!(データ移行ボタン、ポチ)」と祈ることになるのかなと思っていましたが、一旦全データ移行してしまって、後からいくらでも対応ができる状況を作れたことは、データ移行周りの不安を大きく軽減してくれました。
実際どうやってデータ移行するのよ問題
移行対象データの選別方法が決まったとして、実際のデータ移行をどのように行うかも考える必要があります。
「カスタム社員名簿」と「組織図」のインフラ環境としては、それぞれ別の Google Cloud のプロジェクトになっています。つまり、別プロジェクトの、全く異なるスキーマの CloudSQL 間でデータを移行する、というのが今回のミッションです
当初の案
まず最初に検討したのは、
- 「カスタム社員名簿」の DB に「名簿」からアクセスできるようにインフラ面で変更を加える
という案でした。

しかし、この案に関してはセキュリティ懸念が大きいとして、あまり深くは検討しないようにしました。
次なる案
次に思いついた案としては、
- 「カスタム社員名簿」の DB のデータをダンプして、「組織図」側に新たに作成した DB でリストアをする
- リストアされた DB から Rails で頑張るなどして移植先の DB にデータを移行する
というものです。
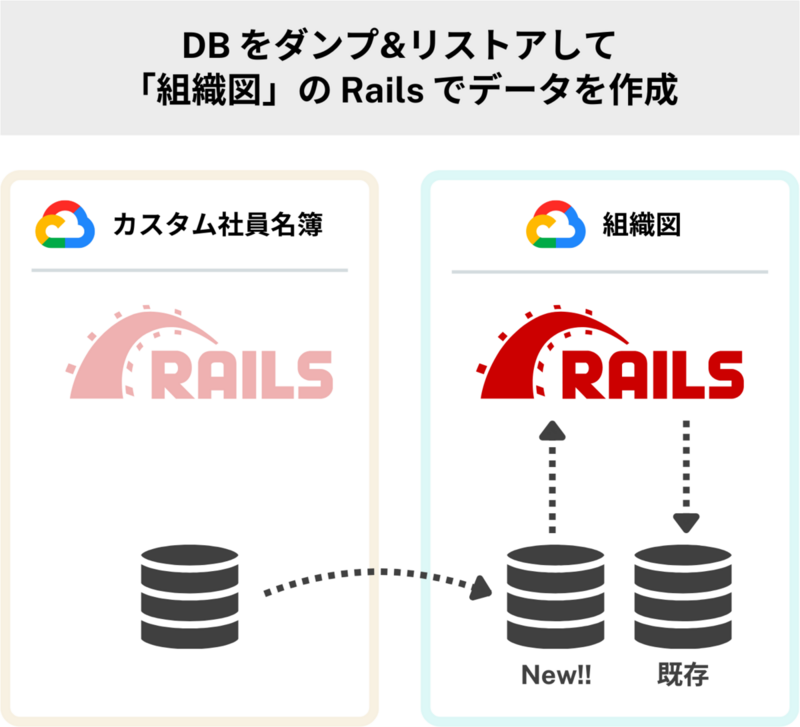
DB のリストアまではイメージしやすいのですが、実際はデータをリストアしてゴールではなく、「組織図」の本来の DB にデータを適宜移植していく必要があります。結局、このデータの移植はどのように行うべきなのでしょうか。
SmartHR のプロダクトは Ruby on Rails で構築されていて、DB のデータは基本的に Active Record を介して操作されます。今回も、 DB のデータの移行ということで、生 SQL を実行するのではなく Active Record を経由させたいところです。
しかし、それを実現するのはなかなか骨が折れることがわかりました。Rails で2つの DB を扱うこと自体はできますが、そのためには移植元である「カスタム社員名簿」側の Model のソースコードも全て移植してくる必要があります。その上で、移行元の Model から移行先の Model にデータを渡してレコードを作成......といった形になります。
これでもできないことはないですが、移行先である「組織図」側でのアプリケーションコードに対する変更点が多く、また大掛かりな DB のマイグレーションが発生することになったりと、やや作業難度が高い印象がありました。
最終案
そこで、最終的にたどり着いたのが、
- 「カスタム社員名簿」のデータで必要なものを JSON 形式で GCS (Google Cloud Storage) に出力する
- 「カスタム社員名簿」の GCS から「組織図」の GCS にファイルを転送する
- 「組織図」上で GCS から JSON ファイルを読み出し、DB にデータを作成する
というものです。
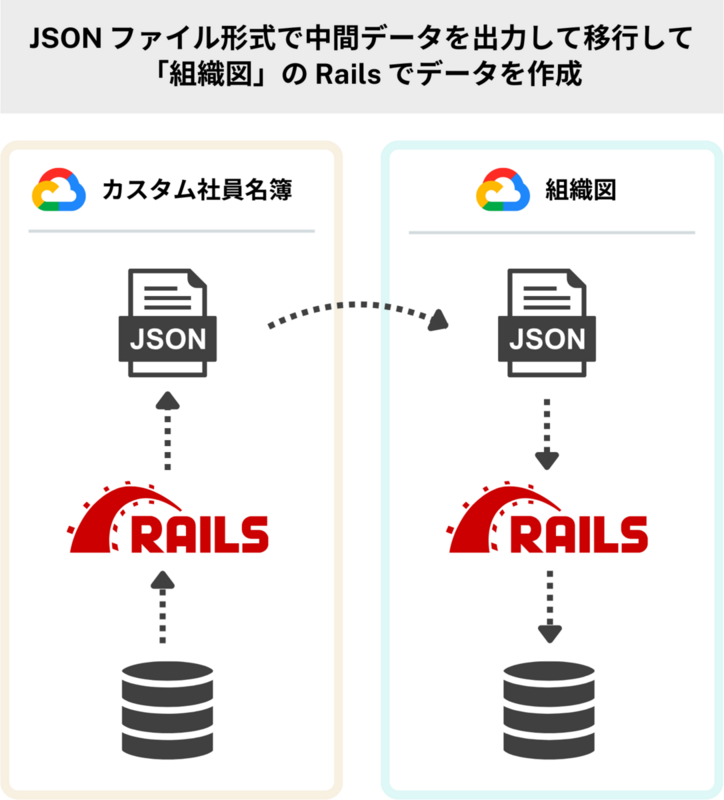
こうすることで、最初の JSON へのデータの吐き出しと、最後の JSON ファイルからデータを作成する工程は、どちらも慣れ親しんだ Active Record を介して行うので、実装の不安はなくなります。「組織図」機能では組織図・名簿の作成に Sidekiq (Rails で非同期処理を行うための gem) が使われていますが、移行データの作成処理を既存の Sidekiq の worker の流用で実装できたこともこの方式の良かったところです。
また、データの移行に関しては、扱うものが SQL データからただの JSON 形式のファイルに変わったことで、扱いやすさが各段に上がりました。
餅は餅屋ということで、「データの移行」と「データの呼び出し・書き込み」のプロセスを分け、それぞれを得意とする技術を使ってあげることで、比較的シンプルなデータ移行方法となったかなと思います。
データ移行の実行時間長すぎるけどどうするのよ問題
さて、データの移行方法が決まったわけですが、このデータの移行作業に実際どれくらい時間がかかるのかがわかっていないと、データ移行のスケジュールは立てられません。
まずは計測
そこで、本番での大まかな実行時間を見積もるために、ステージング環境のインフラスペックを本番と同等にし、ステージング環境に対してデータの移行作業を実行しました。
おさらいをすると、データの移行の流れは、
- 「カスタム社員名簿」のデータで必要なものを JSON 形式で GCS に出力する
- 「カスタム社員名簿」の GCS から「組織図」の GCS にファイルを転送する
- 「組織図」上で GCS から JSON ファイルを読み出し、DB にデータを作成する
です。
つまり、計測の観点としては、
- 「カスタム社員名簿」の全データを JSON 形式で出力する時間
- GCS 間で JSON ファイルを転送するのにかかる時間
- JSON ファイルから「組織図」側でデータを作成するのにかかる時間
の3つとなります。
1つ目の「カスタム社員名簿」からの JSON 出力に関しては、名簿関連の設定データを DB から読み取って出力するだけなので、そこまで時間はかからないと予想していましたが、結果としては4分程度で終わりました。実行時間はデータ量に比例するので、本番環境のデータ量で換算したところ、3時間程度で終わることが確認できました。
2つ目の GCS 間でのファイル移動に関しては、計測するまでもなく、ほとんど待ち時間なしで終了しました。ちなみに、この作業には Google Cloud の Storage Transfer Service を使ったのですが、公式では転送データが 1TB 未満の場合は gsutil を使用することが推奨されているようです。今回は全ファイル合わせても数百 MB 程度だったので、オーバースペックな移行方式だったかもしれません。
問題となったのは3つ目の「組織図」側でのデータ作成の処理時間でした。ステージング環境で実行したタイミングでは88分もかかってしまい、これを本番環境のデータ量で換算すると、なんと53時間もかかってしまうという結果になってしまいました。
Sidekiq の worker を使って実行するとはいえ、これだけの長い時間データの作成処理を実行し続けるのは、やはり不安が出てきます。これはあくまで推定時間ということを考えると、場合によってはもっと時間がかかってしまうことも考えられます。
インフラを増強して再計測
そこで、まずはシンプルにインフラを増強して、処理がどれくらい早くなるかを計測してみました。
ステージング環境のインフラスペックは本番と同じにしてあったので、そこからさらに sidekiq の worker が動いている AppEngine の台数を2倍にし、CloudSQL のメモリと vCPU も2倍の数字にしました。
こうすることで、処理時間は半分とまではいかなくとも2/3程度になるのではないかと予想していたのですが、結果としてはインフラ増強前 (88分) とほぼ同じ、87分という結果でした。
しかし、実行内容の内訳をよく見てみると、一つの巨大な名簿データが処理のボトルネックになっていることがわかりました。そして、その名簿データ以外を対象にすると、スペックを上げる前は40分で処理が終わっていたところ、スペックを2倍にしたときは25分で処理が終わっていることもわかりました。
さらに、AppEngine の台数を4倍にし、CloudSQL のスペックを4倍に上げても同様の現象が確認できました。 (巨大な名簿に対する処理時間は変わらず、それらを除くと処理の実行時間は短くなる)
この時点でチームとしては下記のように理解しました。
- Sidekiq の並列実行数 (スレッド数) を増やすことは処理時間を早めることに繋がる
- DB の性能を高めても処理時間は早くならない (ボトルネックは別のところにある)
実行チャンクをいい感じに分ける
もともと、データの作成処理に関してはすべて一気に実行するのではなく、何回かのチャンクに分けて実行しようと考えていました。そうすれば、何かしらのエラーが発生して再実行が必要になった場合でもダメージが少なくて済むからです。
前述の計測結果から、巨大な名簿のデータが全体の実行時間の決定要因となることがわかっています。つまり、並列処理数を増やして99件の名簿のデータ作成を高速で終わらせたとしても、1件の巨大な名簿があるだけで、その実行チャンクの終了時間は遅くなってしまうということです。
つまり、逆に言えば、並列処理数を増やしつつ、最初の実行チャンクで巨大な名簿データのみに絞って実行することで、チャンクごとの実行時間にできるだけ無駄がなくなるように処理できるようになるということでもあります。
そのため、結論としてチームとしては下記のような作戦でいくことにしました。
- 処理高速化のために Sidekiq のスレッド数を4倍に増やす
- 処理時間には影響しないが、過負荷対策として CloudSQL のスペックも4倍に上げる
- 巨大な名簿データの作成を同じ実行チャンクにまとめて実行することで、増えたスレッドを効率的に使う
この作戦によって、当初は53時間だった見積もり時間は、最終的には約4時間にまで短くなりました。
余談ですが、データ移行時は Sidekiq の process_limits を指定することで、プロセスごとの最大同時実行ジョブ数を制限できるので、こちらも忘れずに設定しておきました。(これを忘れると大量のジョブがキューイングされて、ユーザーが実行した別のジョブの邪魔してしまう可能性があります)
結果
実際のデータの移行作業はどうだったのかといえば、上記の工夫を盛り込んで万全の体制で臨んだ結果、かなり巻きで作業を終わらせることができました。
データ移行の日程は、2024/02/05 (月) の夜から 2024/02/08 (木) までの3日ちょっとの間に終わらせる予定になっていましたが、実際は 2024/02/06 (火) の夜までにはすべてのデータの移行作業が終わり、残りの期間は移行の際に発生したエラーの調査に当てることができました。(エラー自体も数件だけで、いずれも対応不要のものでした。)
特に、当初53時間という見積結果が出て震え上がっていた「組織図」側での Sidekiq の処理は、結果として3時間半で終わらせることができました。
データ移行周りの工夫はこれ以外にも色々とやってはいたのですが、この記事ではその中でも特にクリティカルだったものを紹介してみました。
こういったデータ移行作業というのは、アプリケーション事情、インフラ事情、社内体制事情など、各方面の事情を前提として進められるものです。
ゆえに、今回紹介した工夫もそこまで再現性のあるものだとは思いませんが、なにかの拍子にデータ移行担当になってしまった場合はこの記事のことを思い出してみてください。
We Are Hiring!
SmartHR では一緒に大量のデータ移行をやっていく SmartHR を作りあげていく仲間を募集中です!
「フン...話だけでも聞いてやるか」となったら、カジュアル面談でざっくばらんにお話ししましょう!