
SmartHRで届出書類という機能を担当しているプロダクトエンジニアのsato-sと申します。 今日は、以前私が調査にとても苦労したパフォーマンス上の問題の話を紹介したいと思います。
TL;DR
- PostgreSQLのアップグレードを実施した
- アップグレード後、今までは問題のなかった特定のクエリの実行に1時間超かかり、DBのCPU使用率がピッタリ100%に張り付くようになった
- 色々調査した結果、PostgreSQL上の型キャストの場所のせいで、良くないクエリプランが選択されることが原因だった
- 型キャストの場所には気をつけよう
PostgreSQLのアップグレードと挫折
SmartHRでは基本的にWebアプリケーションのデータベースとしてGoogle CloudのCloudSQLによって提供されるPostgreSQLを利用しています。 私の担当している届出書類機能では、利用中のPostgreSQLのバージョン11が古くなりつつあったため、新しいバージョン14へのアップグレードを計画していました。
私達のチームでは、アップグレードの手順書を作成し、production環境の前にstaging環境でアップグレード作業を実施しました。 CloudSQLがin-placeでアップグレードする機能を提供してくれているのもあり、アップグレードの作業自体は滞りなく完了し、私は気分良く仕事を終わろうとしていました。
ところが、その後悲劇が起こり出しました。
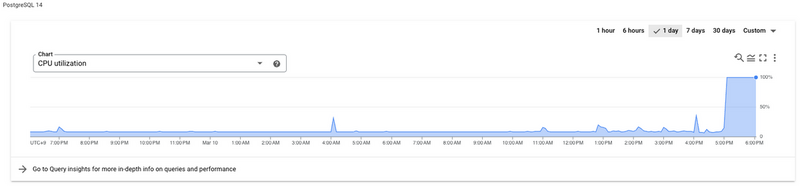
データベースインスタンスのCPU使用率の上昇とSlow Queryを知らせるアラートがひっきりなしにSlackに飛んで来たのです。
CloudSQLのダッシュボードを見ると、CPU使用率がピッタリ100%に張り付いていました。
初期の調査と原因クエリの特定
CPUが100%になっている原因を探るため、私はまずpg_stat_activityを見てみることにしました。
pg_stat_activityはPostgreSQLがサーバープロセスの活動を見るために提供しているビューで、PostgreSQLが現在実行しているクエリの情報なども表示してくれます。
これを確認すると、ある特定のクエリがとてつもなく重くなっており、一時間以上かかっても結果が返ってこなくなっていることがわかりました。
CPU使用率が100%になっていた原因は、このクエリが大量に実行され続けているためでした。
このクエリはアプリケーションを利用するとほぼ必ず実行されるAPIによって投げられるクエリであり、PostgreSQLアップグレード後に、たまたまこのクエリが実施され始めたというようなことは考えづらいものでした。以前はまったく問題なかったクエリがいきなり一時間以上かかるようになったことからPostgreSQLのアップグレードが、この現象を引き起こしたことはほぼ間違いないと考えられました。

また、このクエリはORMによって生成された非常に長いクエリで、パッと見て何が悪いかを特定することは困難でした。 そもそも、以前は全く問題なく動作していたはずのクエリであり、クエリ自体に問題があるかもわからない状態です。 このため、一旦この時点でstaging環境のPostgreSQLのアップグレードを諦め、元のバージョン11に戻すことになりました。
原因クエリの分析
幸いにもこの問題はproductionではなくstaging環境で発生しました。
このためデータベース内に実際のユーザーのデータは入っておらず手元のMacにデータをダンプしてきて問題の再現を試してみることができます。
ところが、実際にダンプしてきたデータベースに対して問題になったSQLを流してみると、クエリの実行は279ミリ秒で完了してしまったのです。
$ time psql -U postgres -f 問題になったSQL.sql > /dev/null ________________________________________________________ Executed in 279.07 millis fish external usr time 3.89 millis 0.04 millis 3.85 millis sys time 5.85 millis 2.22 millis 3.63 millis
stagingでは1時間以上かかっていたクエリが279ミリ秒で完了しているということは何らかの原因で問題の再現ができていないことを意味していました。
実は、私には再現できていない理由に心当たりがありました。それはPostgreSQLのRow Level Security(以下RLS)という機能です。
SmartHRは同じアプリケーションを複数のお客様に提供するマルチテナントのサービスです、
私達のチームでは、各テナントのデータの分離をさらに強固にするためこのRLSという仕組みを利用しています。(参考)
先程の再現の際にデータベースのスーパーユーザーを使っていたのですが、スーパーユーザーはあらゆる制限を迂回してしまうため、RLSが有効に働きません。
あたらためて一般ユーザーを使いRLSを有効にした状態で再現試験を行うと、以下のように263秒かかりました。
$ time psql -U 一般ユーザー -f 問題になったSQL.sql > /dev/null ________________________________________________________ Executed in 263.26 secs fish external usr time 3.93 millis 0.06 millis 3.87 millis sys time 5.38 millis 2.20 millis 3.17 millis
staging環境では1時間超かかっていたことに比べると高速ですが、発生した問題は再現できていそうでした。
(staging環境より高速な理由として、会社支給のMacがかなり高性能、stagingと違ってクエリが1多重しかないなどがあります。)
スーパーユーザーでの実行という良くない再現手順を行ったことで、偶然にも問題になったSQLが遅かった原因はRLSとなんらかの関係があるということがわかりました。
クエリプランの分析
更に原因の詳細を特定するためクエリプランを確認しました。
するとクエリプランの中でMaterializeというプランの実行に、ほとんどの時間をかけていることがわかりました。
以下の例ではMaterializeというプラン単体で4分39秒もかかっています。
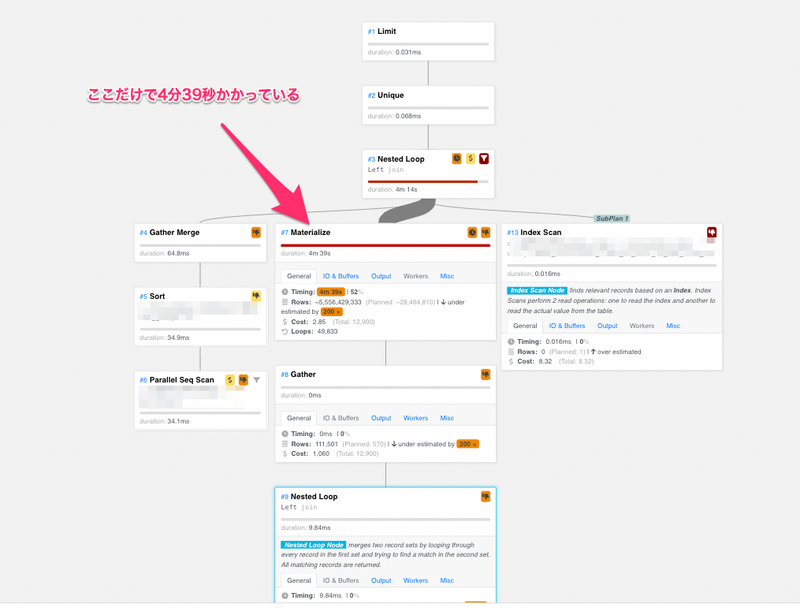
※なお上のようなクエリプランの可視化のためにpev2というOSSを使用させていただきました。どの辺が原因で遅いのかに関するヒントも表示してくれるので、この調査の中とても助けられました。
すでに、この問題にはRLSが何らかの形で関係しているということがわかっているため、RLS無効のときのクエリプランも比較のため確認してみました。 すると先程までのRLS有効の場合のプランとことなり、Materializeというプランが存在しないことがわかります。(このため、このクエリは一瞬で終わります)
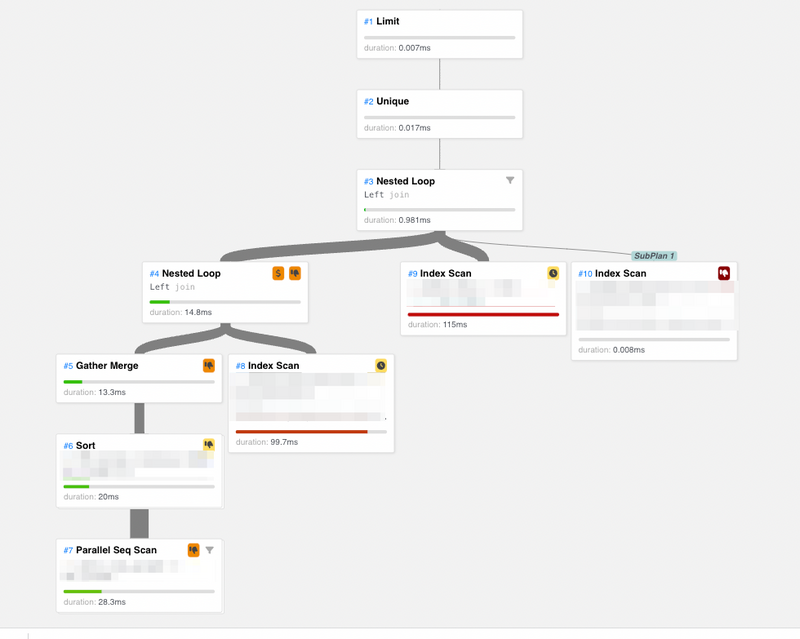
このことから、RLSはクエリを直接的に遅くしている原因ではなくRLSが有効になることによって、Materializeという(この状況では)悪いクエリプランが選択されてしまっていることが推測できました。
この推測を確かなものにするために、次にRLSを有効にした状態でMaterializeというプランを選択しないような状態でクエリを実行してみました。
以下のようにset文でパラメーターを設定しておくと、PostgreSQLはMaterializeの選択を避けてくれます。
set enable_material TO OFF;
するとクエリの実行は一瞬で完了し、その時のクエリプランは以下のようになりました。
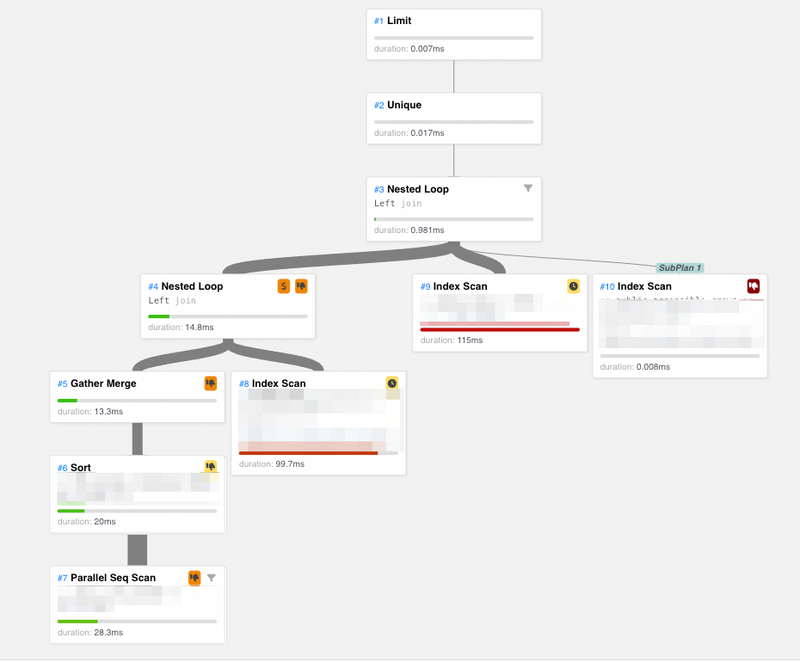
こちらは、RLSを無効にした場合のクエリプラントほぼ同じものになりました。 やはり、RLS自体はクエリを遅くしている直接の要因ではなく、RLSが有効になることによってMaterializeというプランが選択されることが、クエリを遅くしている原因のようです。
なぜMaterializeが選択された?
では、なぜMaterializeという遅いプランがPostgreSQLによって選択されてしまったのでしょうか?
それを確認するためにMaterializeのコスト推定と実際の実行時間を確認しました。
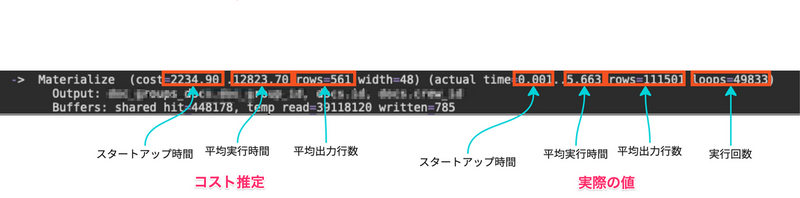
注目すべきは、平均出力行数のズレです。 コスト推定の段階では、Materializeから出力される行数が平均561行であると見積もられています。 しかし実際は平均して111501行という見積の200倍近い行数が出力されています。 このコスト推定のミスがMaterializeという、(このケースでは)遅いプランの選択に繋がってしまっています。
では、なぜ平均出力行数を見誤ってしまってのでしょうか? これはMaterializeより下位のプランに原因がありました。 Materializeから下方にプランを辿っていくと、どのプランも平均出力行数の推定値が実際の値とかなりズレていることがわかりました。 下位のプランが平均出力行数を過小に見積もってしまった結果、その上位のプランもまた平均出力を見誤ってしまっているようです。
結局、Materializeの下位のParallel Bitmap Heap Scanというプランが、この平均出力行数の誤りの出発点となっていました。

なぜParallel Bitmap Heap Scanが平均出力行数を見誤ったか?
では、なぜParallel Bitmap Heap Scanは出力行数を見誤ってしまったのでしょうか? このParallel Bitmap Heap Scanのプランは以下のようになっていました。
-> Parallel Bitmap Heap Scan on public.テーブル名 (cost=1234.48..9911.87 rows=234 width=48) (actual time=0.753..17.227 rows=37167 loops=3)
Output: テーブル名.id, テーブル名.tenant_id, テーブル名.カラム名, テーブル名.カラム名, テーブル名.カラム名, テーブル名.カラム名
Recheck Cond: (テーブル名.tenant_id = '0393b184-b1e2-4881-a2eb-9d96af9ea829'::uuid)
Filter: ((テーブル名.tenant_id)::text = current_setting('tenant_level_security.tenant_id'::text))
-- 略
重要なのはFilterの部分です。 あるテーブルをスキャンしようとする際にPostgreSQLは、この条件からParallel Bitmap Heap Scanが出力する行数を推定するはずです。
このFilterの部分は、以下のようにあるテーブルをtenant_idというカラムで絞り込むというものになっていました。
Filter: ((テーブル名.tenant_id)::text = current_setting('tenant_level_security.tenant_id'::text))
この条件は、まさにRLSによってテナント間の分離を担保するために追加されているものでした。 RLSが無効になった際に、問題になったSQLがすぐに完了したのは、この条件が無効になっていたためだと考えられました。
なぜFilterの条件は正しく出力行数を見積もることができかなったのか?
では、なぜこのFilterの条件は正しく出力される行数を見積もることができないのでしょうか?
もう一度この条件をよく見ると、少し怪しい点があります。
Filter: ((テーブル名.tenant_id)::text = current_setting('tenant_level_security.tenant_id'::text))
それは、上の条件の左辺をキャストしている点です。
該当のテーブルのtenant_idというカラムはPostgreSQLのUUID型になっていました。
一方で、右辺のcurrent_settingはtext型を返す関数です。
この2つの型を合わせるために左辺がtext型にキャストされています。
このような=をつかった条件のスキャンの際、PostgreSQLは
most common values (以下MCVs)
という仕組みを使って出力される行数を推定するようです。
このMCVsは、高い頻度でテーブルに現れる値と、その頻度を覚えておき、=の比較
が行われた時に、その頻度をもとに出力される行数の推定値を計算する仕組みでした。
しかし、このFilterの条件では左辺のtenant_idに対してキャストという値の変換が行われているため、このMCVsによる出力される行数の推定が機能しなくなってしまった可能性が考えられました。
実際にMCVsによって、利用される値と頻度の組み合わせは以下のように確認することができます。
# SELECT attname, inherited, n_distinct, most_common_vals,most_common_freqs FROM pg_stats WHERE tablename = 'テーブル名' and attname = 'tenant_id';
-[ RECORD 1 ]-----+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
attname | tenant_id
inherited | f
n_distinct | 17
most_common_vals | {9600dc18-b3a7-4f59-b0ae-4951f05358fe,0393b184-b1e2-4881-a2eb-9d96af9ea829,fcbf4f89-fcaa-41c1-aac0-9d3078877b27,ffc562c6-0e9d-4b16-b28d-fb077402e53e,0e5d7bef-4676-4346-9780-a9dee9f01a2d,ddf32ba8-9247-4372-9a16-cbb11555104f,da502501-07ae-4a0f-9225-52c9b6f7a2b0,1a015750-12bd-442e-b941-33a533a77be3}
most_common_freqs | {0.70703334,0.1963,0.05403333,0.035733335,0.0026333334,0.0016333334,0.0009,0.00046666668}
上で表示されたmost_common_freqsの値が、テーブルの全体行数の推定値と掛け算されることで、このFilterから出力される行数が推定されるはずです。
実際に計算してみると、上記のmost_common_freqs値は正しく、もしこの値が使われていれば、このFilterから出力される行数は、ほぼ正確に見積もれることがわかりました。
キャストの場所がコスト推定に影響することの実験
キャストの位置がコスト推定に影響することを確認するために、もっとシンプルな例で実験してみましょう。 次のようなtenant_idというカラムを持つテーブルを作成してみます。
CREATE TABLE IF NOT EXISTS sample ( tenant_id integer, id integer );
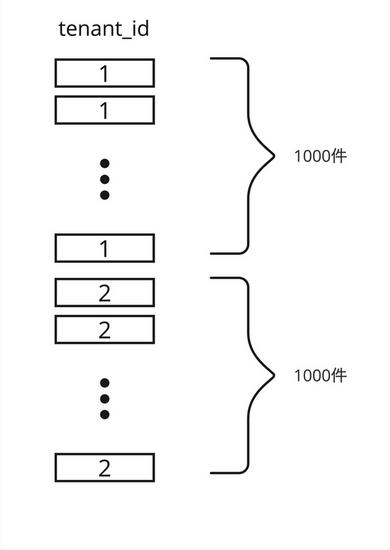
次に以下のようにテーブルtenant_id=1のデータと2のデータを1000件ずつ投入してみます。
-- tenant_id = 1 の行を1000行追加 INSERT INTO sample (tenant_id, id) VALUES (1, (generate_series(1,1000))); -- tenant_id = 2 の行を1000行追加 INSERT INTO sample (tenant_id, id) VALUES (2, (generate_series(1,1000))); -- 統計情報の更新のためANALYZE ANALYZE sample;
この時、このテーブルはtenant_id=1と2のレコードを半分ずつ持っていることになります。
tenant_idというカラムをキャストしてSELECTをしてみましょう。
# explain select * from sample where tenant_id::text = '1'; QUERY PLAN -------------------------------------------------------- Seq Scan on sample (cost=0.00..44.00 rows=10 width=8) Filter: ((tenant_id)::text = '1'::text) (2 rows)
上にrow=10とあるように、tenant_id=1のレコード数を10件と推定してしまっています。
実際は1000件のtenant_id=1のレコードがあるので、この推定はかなりズレてしまっています。
今度はtenant_idをキャストせずに、右辺をキャストした状態で同様のクエリを実行してみます。
# explain select * from sample where tenant_id = '1'::integer; QUERY PLAN ---------------------------------------------------------- Seq Scan on sample (cost=0.00..34.00 rows=1000 width=8) Filter: (tenant_id = 1) (2 rows)
するとrow=1000とあるように、正確なコスト推定が行われていることがわかります。
MCVsを確認してみると、以下のようにmost_common_freqsが0.5となり、テーブルのちょうど半分の行がtenant_id=1となっていることをPostgreSQLが正しく認識してくれているのがわかります。
# SELECT attname, inherited, n_distinct, most_common_vals,most_common_freqs FROM pg_stats WHERE tablename = 'sample' and attname = 'tenant_id'; attname | inherited | n_distinct | most_common_vals | most_common_freqs -----------+-----------+------------+------------------+------------------- tenant_id | f | 2 | {1,2} | {0.5,0.5} (1 row)
このようにカラムをキャストするか、その比較対象の値をキャストするかによってMCVsを利用してPostgreSQLが正確なコスト推定を行えるかどうかが変わってくるようです。
考察と修正
この問題は元々PostgreSQLのバージョンを11から14にアップグレードしたことで発生しました。 バージョンが上がるごとにPostgreSQLがクエリプランを選択するためのオプティマイザーは、 より賢いプランを選択するように修正が加えられていっているはずです。 しかし、あらゆる状況でより高速なクエリプランを選択するように修正ができるはずはなく、今回のように 元々のコスト推定値が正しくないようなエッジケースでは、むしろパフォーマンスが悪化するということが考えられます。 今回のアップグレードによって、このようなエッジケースでのパフォーマンス悪化が顕在化したと考えられます。
修正としてはシンプルにカラムではなく、その比較対象の方をキャストするようにキャストの場所を変更しました。
修正前
(テーブル名.tenant_id)::text = current_setting('tenant_level_security.tenant_id'::text)
修正後
(テーブル名.tenant_id) = current_setting('tenant_level_security.tenant_id'::text)::uuid
この修正によって、パフォーマンスが劣化することなく、無事にPostgreSQLのバージョンを14にアップグレードすることができました。
まとめ
キャストの位置のような一見些細に思える問題でも、私が経験したような極端なパフォーマンスの劣化を引き起こすことがあります。 PostgreSQLの条件式の中でキャストをする際には、なるべくカラムをキャストするのではなく、その比較対象の方をキャストすることでコスト推定が正しく行われるようにするのが良さそうです。 また、キャストだけでなく関数呼び出しの場合でも、同様の問題が発生する可能性があるので、こちらも注意が必要です。
We Are Hiring!
こんなパフォーマンス上の問題を一緒に解決していただけませんか?
SmartHRでは、一緒に働く仲間を大募集しています!
ご興味があればこちらから応募下さい。